Features of Parallelism in OneFlow¶
In Consistent and Mirrored view, we have already known OneFlow provides two types of view: mirrored and consistent view and we learned about the consistent view in OneFlow have some special features.
Because in consistent_view, OneFlow provides a logically consistent view. During distributed training, users can freely choose to use data parallelism, model parallelism or hybrid parallelism.
In this article, we will keep going through the special consistent view in OneFlow. We will learn about:
-
Data parallelism in
consistent_viewflow chart. -
Hybrid parallelism in
consistent_viewflow chart. -
The advantages of hybrid parallelism and the applicable scenario.
-
Example of hybrid parallelism.
Network Logical Diagram in Model Training¶
We need to set up a simple multi-layer network first and use this network to discuss parallelism methods. The structure like the figure shows:
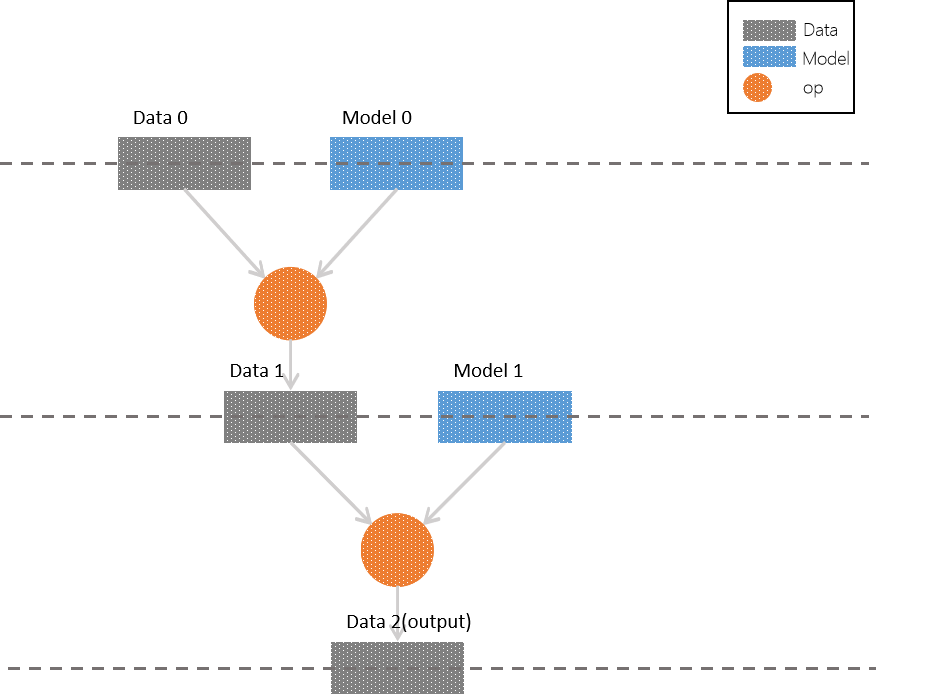
In each layer, we have samples(in grey), models(in blue) and operators(circles) which operating on both of them. To simplify our discussion, we can limit the sample and model as a matrix. The operator applying on them we call it matrix multiplication.
Compare the figure above, we can easily get the logic of the network:
-
The input of layer 0 is
Data 0matrix andModel 0matrix. We applyop(matrix multiplication) and get outputData 1. -
The input of layer 1 is
Data 1matrix andModel 1matrix. We applyopand getoutput. -
The layer 2 is
outputlayer andData 2is the output of network. Of course, it can play as input in a deeper network.
In consistent view, OneFlow supports the data parallelism, model parallelism and hybrid parallelism. We will introduce them in order but hybrid parallelism is the key point.
The Features of Parallelism in Consistent View¶
Data Parallelism¶
We have already known that in consistent view. The default parallelism method is data parallelism. If we choose mirrored view, we can only use data parallelism. If you pass numpy data directly when you call the job function (instead of using OneFlow's [DataLoader and related operators] (... /basics_topics/data_input.md#dataloader)), the difference between them are:
-
In mirrored view, when we use data parallelism. We need to split and reorganize data according to the number of device and use
listto pass and receive data. -
But in consistent view we have the consistency on logic. Splitting data and reorganizing data will be completed by OneFlow framework.
The following figure is in consistent view, using data parallelism to achieve original logical network process:
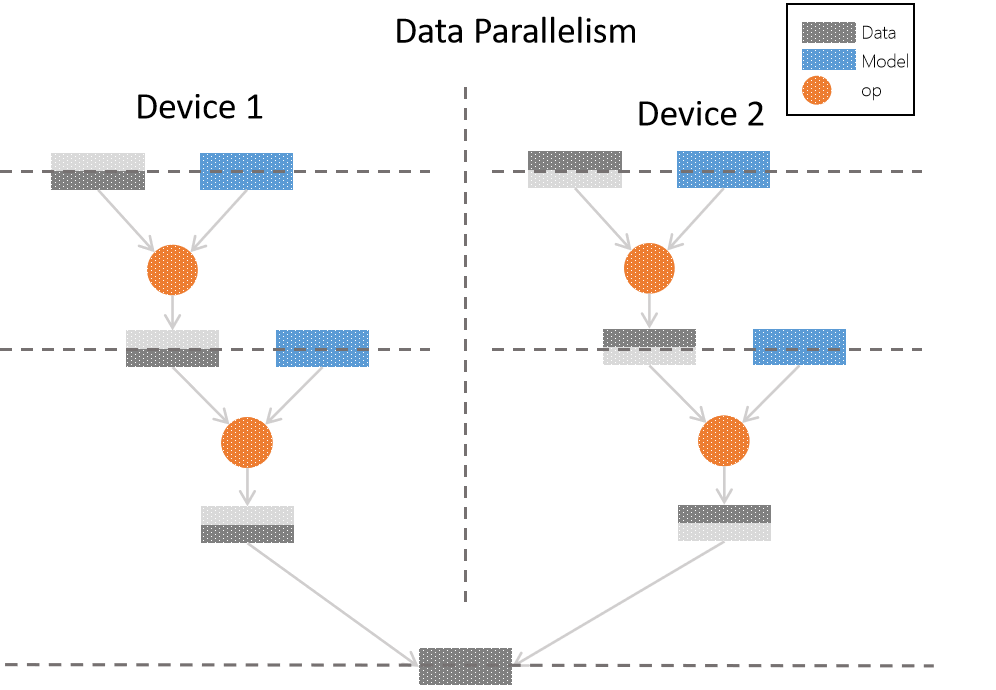
In data parallelism, we use two devices for training. As we use data parallelism, we can see that for each original logical layer, the sample is divided in average to each device. We have a complete training model in each device. The data after splitting are processed by op. Finally we combine the data in each device and get the complete data.
Model parallelism¶
In consistent view, we can choose model parallelism (the configuration details we will talk about it later). The flow diagram is as follows:
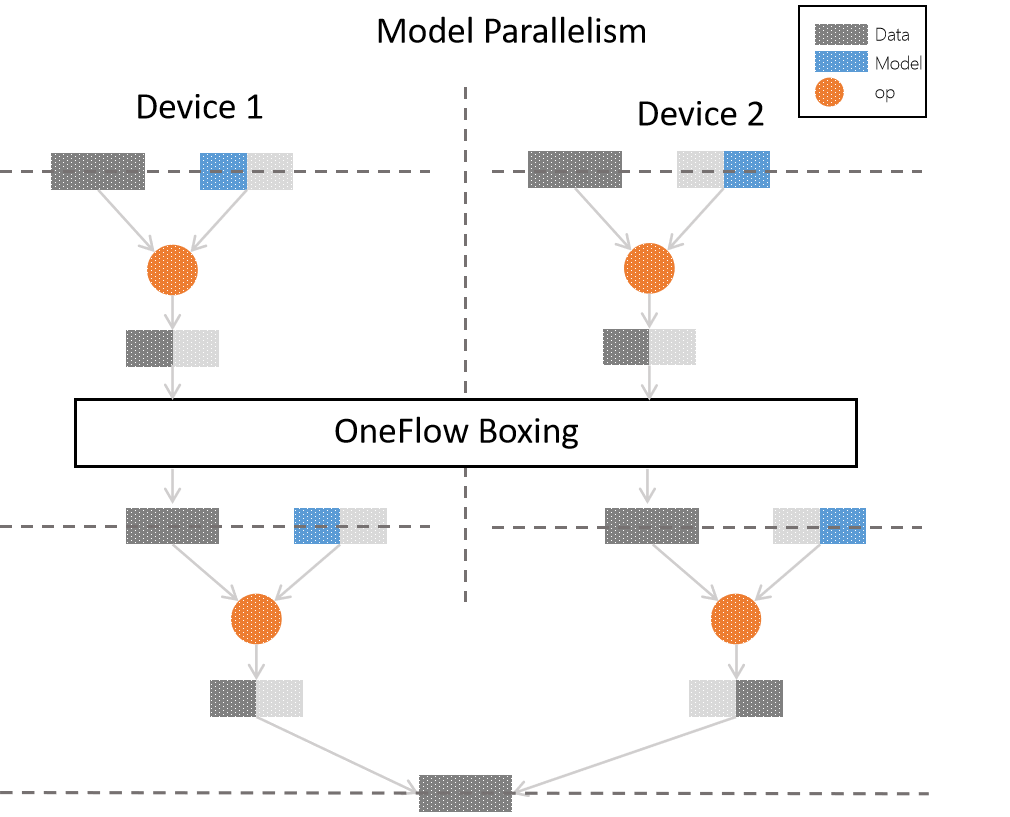
In model parallelism example, we still use two devices for training. In each layer of original logic model is processed by op on part of model and complete data. Then they are combined and we get the complete results.
One thing we need to mention is in above figure. The output from each device on layer 0 cannot use as the input in layer 1: Because in model parallelism, in order to complete the operation. We need partial model and complete data. To solve this problem, OneFlow use boxing mechanism.
boxing will count the data in each node in distributed training and divide or assemble data properly then send to corresponding GPU. Besides the model assembling in model parallelism, boxing is also used for reverse gradient synchronization in data parallelism.
The algorithm in boxing is complex. But it is transparent to users. The Illustration of boxing is just to prevent users from being confused. In this article, we only need to remember that OneFlow will automatically solve the data distribution issue.
Choose the optimal parallelism method¶
The difference between data parallelism and model parallelism is not constant. The sample, model size and model structure decide the performance in distributed training. We need to analyze the data to choose the optimal one.
To be concluded:
-
In data parallelism case, the information needed to be synchronized is gradient in backpropagation. Thus, we need to make sure that synchronization of information between different nodes is faster than calculation inside nodes. For example, the Convolution Layer has few parameters, but it needs large scale of calculation. Therefore, it is suitable for data parallelism.
-
In model parallelism, we divide the logical model equally and send them to each device, which will solve the oversize model problem. Thus it is suitable for the neural network with massive parameters (like fully connected layer) to use model parallelism.
In fact, we can use hybrid parallelism, it means OneFlow uses different parallelism in different parts of training process. For example, at the beginning of the neural network, it has few parameters and a lot of calculation, which makes it better to use data parallelism. For the layer with a lot of parameters, such as fully connected layer, we should use model parallelism. The following figure is the demonstration for the neural network which use hybrid parallelism.
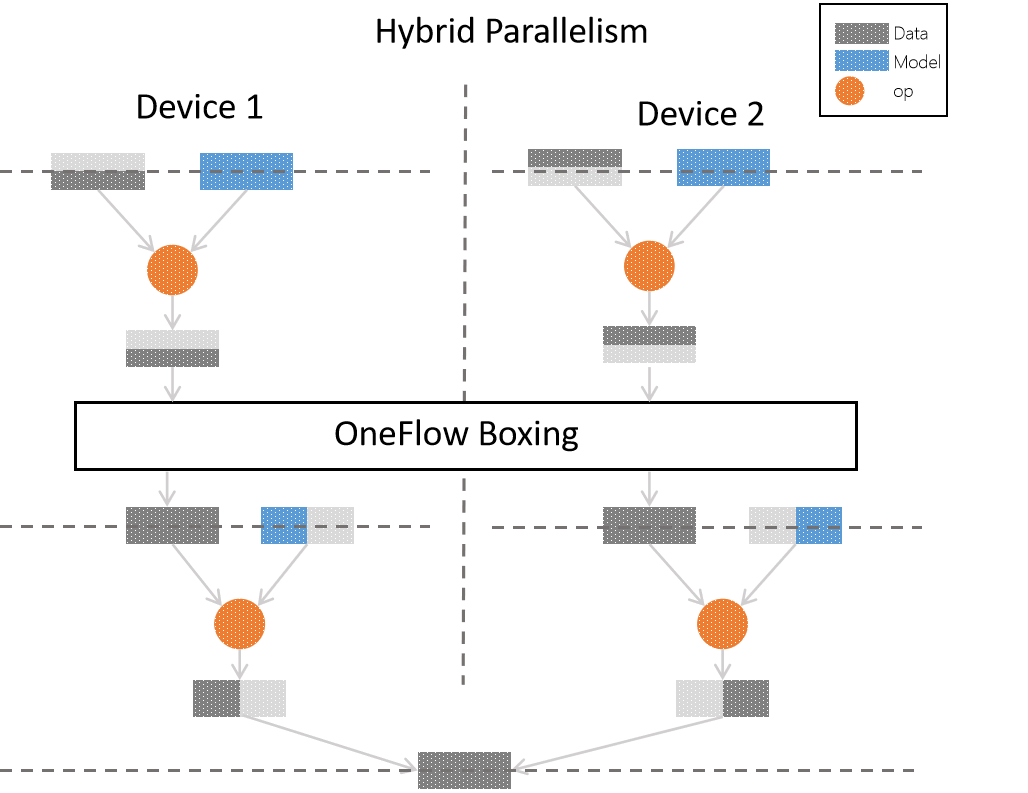
Currently, other popular frameworks either do not support mixed parallelism or require detailed customization. But in OneFlow, the hybrid parallelism distributed training can be configured through simple settings, and the distributed system can also be deeply optimized with the ultra-high degree of freedom pipelining mode.
Hybrid Parallelism Example:¶
Code¶
In consistent view, we use hybrid parallelism to MLP model: the input layer and hidden layer use data parallelism, output layer use model parallelism.
Complete Code: hybrid_parallelism_mlp.py
More explanations can be seen in "code explanations"
Code explanation¶
The above code is modified from the demo in 3 min quick start. Compare two versions of code, we can see it is easy to configure the parallelism method in consistent_view with few codes.
The crucial parts are:
- Use
oneflow.config.gpu_device_numto set the device number in training:
flow.config.gpu_device_num(2)
reshapeandhiddenusing data parallelism as default. The output layer can setmodel_distributeasflow.distribute.split(axis=0)to change to model parallelism:
def mlp(data):
initializer = flow.truncated_normal(0.1)
reshape = flow.reshape(data, [data.shape[0], -1])
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="dense1",
)
return flow.layers.dense(
hidden,
10,
kernel_initializer=initializer,
# dense for column storage with split(0) slicing.
model_distribute=flow.distribute.split(axis=0),
name="dense2",
)
You may be curious about why split(axis=0) is column cutting. To be explained, dense is column-oriented storage in OneFlow. Thus the flow.distribute.split(axis=0) in above code is split by column.
In addition, flow.layers.dense use model_distribute to set parallelism mode, it use the common get_variable to create blob in basic level from inner, and internally calls the more general interface get_variable to create blob. The get_variable interface uses a parameter named distribute to set the parallelism mode.
As you can see, we can change the single machine training program to a distributed, hybrid parallel program with few modifications, which is one of the features that distinguishes OneFlow from other frameworks.
Pipelining Example¶
Besides the model parallelism, OneFlow also provides a more flexible parallelism method called pipelining, it allow user use scope.placement to specify the device of the operator.
In pipelining, some parts of layers of the whole network are on one device and some are on other devices. They work consecutively as relay, switch between devices in different phases.
In the following example, we change a few codes in "Using consistent view in OneFlow" of Consistent and Mirrored view and demonstrate pipelining.
Code¶
Complete Code: hybrid_parallelism_lenet.py
Please refer to code explanation later for more details.
Code Explanation¶
There are only two important lines of code and they have similar effect:
- Use
oneflow.scope.placementto specify the operator run on device 0 inhiddenlayer.
with flow.scope.placement("gpu", "0:0"):
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="hidden",
- Use
oneflow.scope.placementto specify the operator inoutputlayer run on device 1.
with flow.scope.placement("gpu", "0:1"):
output = flow.layers.dense(
hidden, 10, kernel_initializer=initializer, name="outlayer"
)
scope.placement can be found in the API documentation.
Pipelining can allow user to specify which device to be used for each op. It is very useful for user who master the distributed training to optimize deeply.
In addition, OneFlow also provides API oneflow.unpack, oneflow.pack. Combined with the own features of task scheduling in OneFlow, they make the pipelining easier to be used and more efficient. We will introduce them in other article.