OneFlow System Design¶
In this article, we will cover these topics:
- Motivation
- OneFlow feature 1: Runtime based on actor system
- OneFlow feature 2: Compile-time based on a formal description of parallelism
- Summary
Motivation¶
OneFlow is born for performance and horizontal scalability, especially for multi-nodes and multi-devices scenarios. We expect that users can leverage the power of multiple machines and multiple devices in a way as easy as using a single machine with single device, and enjoy the efficiency of linear speedup.
Why does OneFlow focus on the performance and user experience in distributed scenarios? With the development of deep learning, the model becomes increasingly large, and the computing power required to train deep learning models will become higher and higher. The computing power and the memory of a single device are far from meeting the needs of deep learning model training, and multiple machines and multiple devices are required for parallelism speedup.
If the deep learning framework can make multiple interconnected devices work well together and achieve linear speedup, even if the performance of each device is just so so, it can also meet the computing power needs of any scale. This is the so-called horizontal scalability or scaling out. We do believe this is the solution to the increasing need of computing power。
However, the existing frameworks usually focus on the user experience of a single device, and only handle the multi-machine and multi-devices scenarios that works for data parallelism. That is, mirroring the computation graph on a single device to multiple machines and multiple devices, synchronizing model with Allreduce.
For models with a huge amount of parameters such as BERT/GPT-3, users often find it not friendly to use, hard to deploy and not efficient to train models on multiple machines and multiple devices when using existing deep learning frameworks. It is also time-consuming for users to learn how to do distributed training. They also need to care about the synchronization of models between multiple machines and multiple devices. In order to solve the above problems in distributed deep learning, both industry and academia not only improve the deep learning framework itself, but also develop a variety of third-party plugins, such as NCCL, Horovod, BytePS, HugeCTR, Mesh-tensorflow, Gpipe, etc. However, it still can’t meet users' unlimited pursuit to performance.
The core motivation of OneFlow is to make multi-machine and multi-devices distributed training efficiently, and at the same time, to make the distributed training experience as simple as using a single device. Let's introduce the two core ideas of OneFlow, and explain how OneFlow views deep learning training in distributed scenarios.
Runtime based on actor system¶
Key features:
-
Decentralized scheduling
-
Pipelining
-
Data movement as a first-class citizen
-
Overlapping data movement and computation
-
Overlapping control and data logic
OneFlow consists of two stages: Compile-time and Runtime. In the Compile-time, user-defined neural networks and the requested resource are compiled into a static graph execution plan, which is composed of the description of the basic execution unit Actor; During the runtime , each machine actually creates many Actor instances located to its own machine based on the Actor description in the Plan, and then started the Actor operating system. In the training procedure, the basic unit of OneFlow execution is Actor, which corresponds to a node of the static execution graph. The data produced and consumed between Actors are stored in the form of Registers, and the Actors cooperate through message passing.
Decentralized scheduling¶
OneFlow implements decentralized scheduling through the Actor mechanism. In the entire static graph is composed of actors, there is no central scheduler. Each actor only cares about the producer of the data it needs (upstream Actor) and the consumer of the data it produces (downstream Actor). In this way, in the ultra-large-scale distributed training scenario, completely decentralized scheduling can avoid the single-point performance bottleneck with centralized scheduling.
Each Actor has an internal state machine, which updates its status according to the messages sent and received by the Actor. It should be noted that Register is a storage block, which stores the data produced by the Actor, and the message is a lightweight data containing the memory address of the Register storage block. It is message instead of Register that is passed between Actors, in this way, OneFlow runtime achieves zero-copy.
When an Actor receives a new message and decides whether the Register it needs to consume is ready, and it has free Register to write the produced data. If yes, the Actor executes (Act) once and produces some new data.
After action, the Actor sends a message to the consumer Actors who need to consume the produced Register, indicating that "you can read the data I produced"; At the same time, the Actor also needs to return the Register it consumes to its producer, indicating that "I have used up your data and you can recycle it." The state machine inside the Actor is shown in Figure 1.
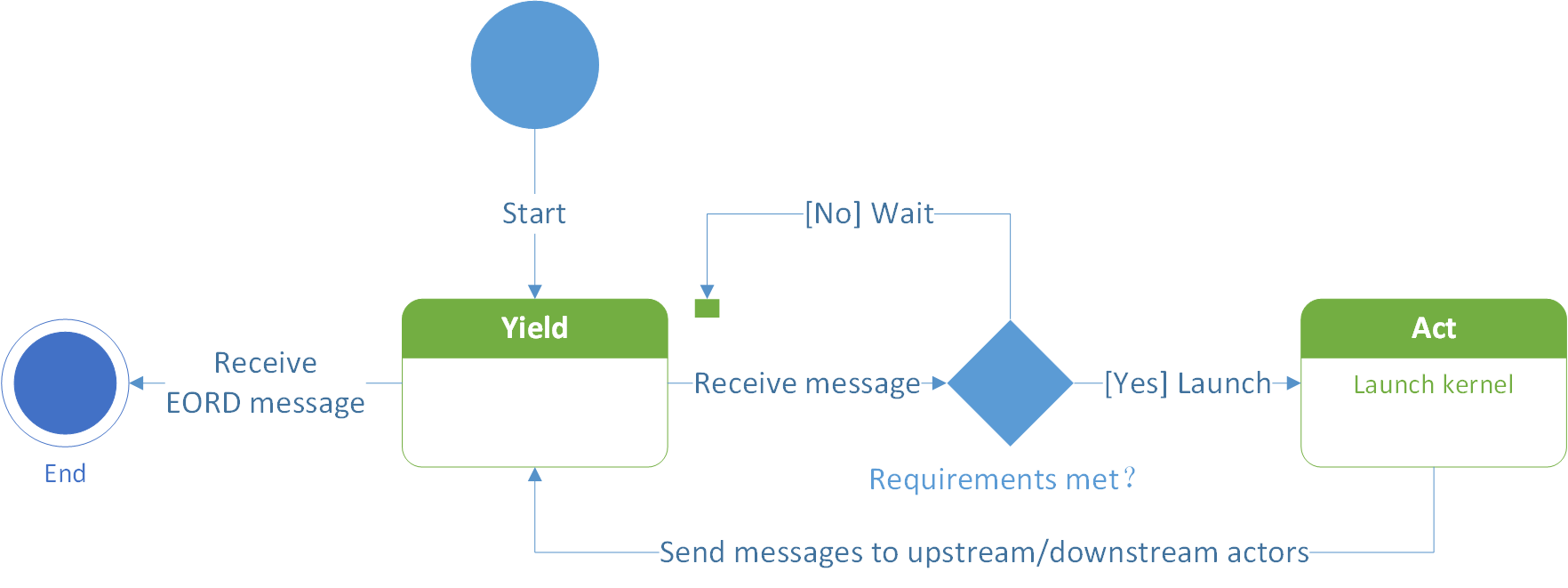
After the Actor starts, it will switch its two states according to the messages sent and received with other actors: waiting state and execution state .
The messages received by an Actor are generally divided into several types:
-
The upstream producer Actor sends a message saying that you can read the data I produce;
-
the downstream consumer Actor sends a message saying that I have used up the data you produced.
When this data are used up by all consumers, it can be recycled as a free block and wait for the Actor to produce a new data in next time.
Whenever receiving a message, an Actor will try to decides whether its action conditions are met with. There are generally two action conditions:
-
Whether all the data to be read are available;
-
Whether there are free blocks that can be used for production. When the action state is satisfied, the actor starts to launch its internal Kernel to consume incoming data and produce some new data.
After action, the Actor will send messages to upstream and downstream:
-
Send a message to the downstream consumer Actor saying that I just produced a piece of data, you can read them;
-
Send a message to the upstream producer Actor saying that I just used up the data you sent me before.
Actors only need to care about upstream and downstream messages to decide whether they can act or not. All Actors form a completely decentralized distributed collaborative network through their own internal state machines and messages exchanging mechanism.
Pipelining¶
In above, we introduced the internal finite state machine of Actors. Message passing and data movement between Actors are implemented by Register. Whether an Actor can act only relates to two conditions:
-
Whether the Registers consumed by itself are readable;
-
Whether the Registers produced by itself have free blocks to write.
For a Register, if we allocate multiple free blocks for it, two adjacent Actors can work simultaneously. In this way, the overlapping of adjacent actors implements pipelining. In an ideal case, the initiation interval of the entire static execution graph is the execution time of the bottleneck actor's each action, the execution time of all the other actors will be hidden through the pipelining.
Let's take an example to explain how the pipelining of the Actor system works. Figure 2 is an execution sequence diagram of a computation graph composed of 3 Actors (a, b, c). The green Regst square represents the Register block being occupied, and the white Regst square represents the free block of the same Register.
-
At Time0, Actor
aproduces a Regst_a_0, and Actorband Actorcare in waiting state because they have no readable Register. Here we assume that the execution time of each Actor is the same. -
At Time1, Actor
asends a message to Actorbsaying that you can read the Regst_a_0 that I produced. Actorbreceives the message and checks whether there is a free block available in the Registerbowned by itself, and finds that there is an available Regst_b_0 , so Actorbexecutes at Time1, reading Regst_a_0 and writing Regst_b_0; at the same time, Actorawill also check whether it has a free block to write, and finds that it has a free block to write, so Actorawill also begin executing at Time1, writing Regst_a_1. (It should be noted here that Regst_a_0 and Regst_a_1 logically belong to the same Register, but they are spatially divided into different free blocks. In deep learning training task, Regst_a_0 and Regst_a_1 store data belonging to different batches produced by a same producer.) So Actoraand Actorbwork in parallel. Actorcis still waiting because there is no data to read. -
At Time2, Actor
bhas produced Regst_b_0, so it sends a message to the downstream consumer Actorcthat you can read the Regst_b_0 I produced, and at the same time sends a message to the upstream producer Actorathat I have consumed your Regst_a_0 . At the same time, Actorasends a newly produced Regst_a_1 to Actorb. Actorbchecks that it still has Regst_b_1 being free, so Actorbstarts to read Regst_a_1 and writes Regst_b_1; Actorcreceives Regst_b_0 and finds that it has Regst_c_0 being free, so Actorcstarts execution, reading Regst_b_0 and writing Regst_c_0; Actorareceives Regst_a_0 that Actorbhas used up and returned the ownership, and checks that all consumers of Regst_a_0 are used up, so Regst_a_0 is recycled and marked as a free block, and Actoracan continue to execute and write Regst_a_2.
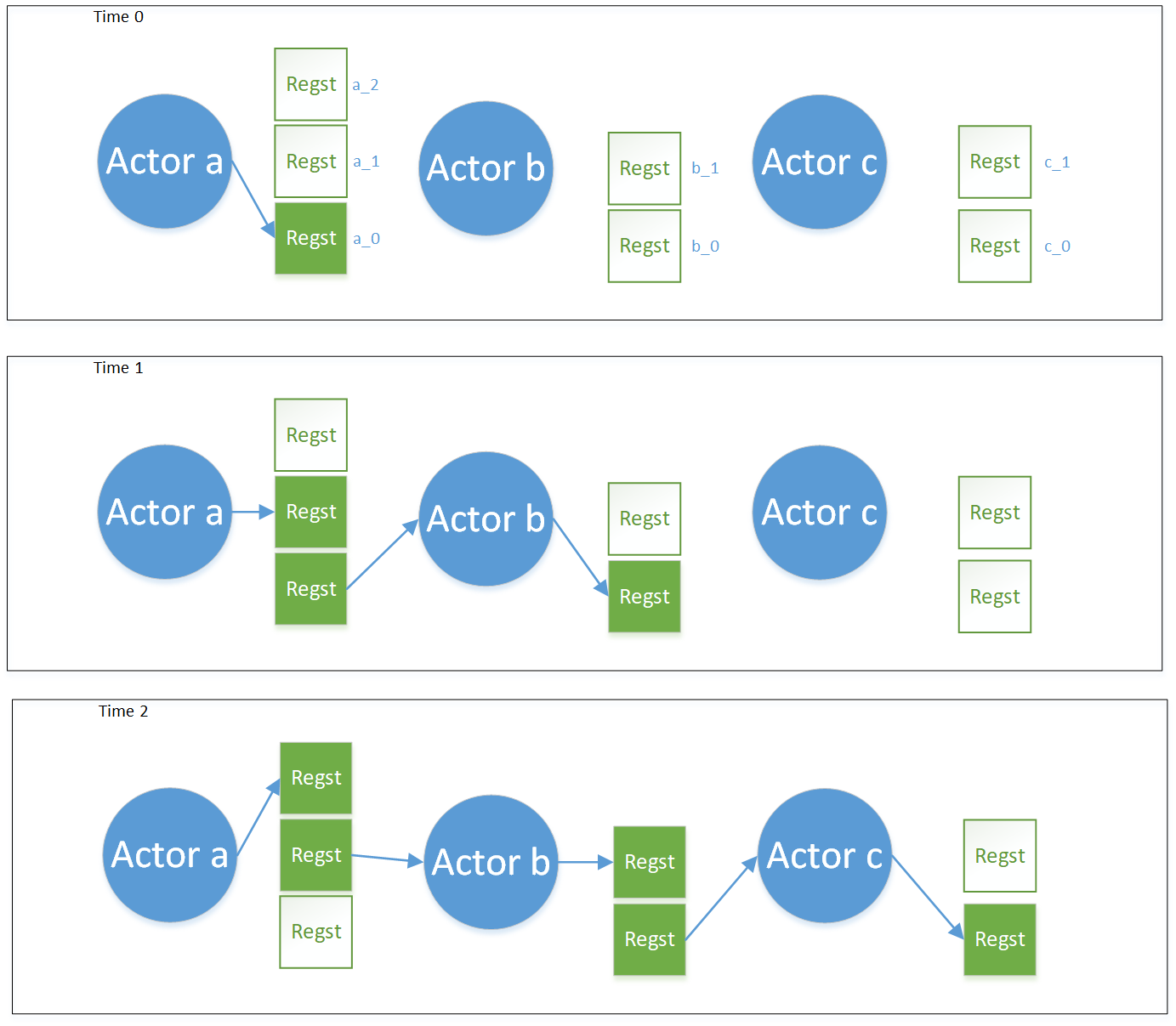
In the above example, at Time2, Actors a, b, and c are all working simultaneously. In typical deep learning training job, Regst_b_0 and Regst_c_0 at Time2 store the data of Batch 0, and Regst_a_1 and Regst_b_1 store the data of Batch 1. Regst_a_2 stores data of Batch 2. By the design of a Register with multiple free blocks, the Actor naturally supports pipelining.
Here we raise a further in-depth problem: in OneFlow, the execution of the entire data flow is like a network, and the data flow throught the network and completes the computation. How to slow down the producer's production if it is too fast for the consumer to consume, and how to avoid the case if the producer's production is too slow, and consumers get hungry. This problem involves planning for computing, memory, and transmission bandwidth, so that the bottleneck of the system is as wide as possible. It relates to flow control and resource allocation (For example, how many memory block quotas are allocated to the Register of each Actor). This is a critical problem which has been solved by the OneFlow system.
Data movement as a first-class citizen¶
In a distributed environment with multiple machines and multiple devices, the data movement between machines and devices is often the bottleneck affecting the horizontal scalability of the system. Only if the movement cost can be overlapped by the computation, can distributed deep learning training achieve the ideal linear speedup. Compared with other frameworks, OneFlow regards data movement as important as computation, thus proposing the idea of "data movement is the first-class citizen".
Most attention of the conventional frameworks is paid to computation in compile-time. The existing frameworks treat the data movement occuring implicitly behind the scenes. Therefore, the arrangement of overlapping computation and movement is ignored while performing the static analysis of the computation graph. OneFlow explicitly expresses the data movement in the computation graph and treat data movement and data computation equally important in static analysis to maximize the overlapping between data movement and computation.
In runtime, data movement operations are also carried out by Actors. In addition to actors used for computation on devices, there are also Actors responsible for data movement between host memory and device memory, network Actors for network communication between machines, Actors responsible for data splitting, merging, and replication, Actors responsible for fetching and reading data from disk, and Actors responsible for loading and saving the model, etc. Many other frameworks make data loading, synchronization of model gradients, networks, model loading updates, etc. into a separate module, but in OneFlow, all such complicated functions are implemented in a static execution graph composed of Actors. The design of OneFlow is simple, elegant and efficient.
Figure 3 shows that, in the runtime of OneFlow, how the data are moved from the producer to the consumer on another machine if without GPU-direct.
Exploit parallelism as much as possible¶
In the design of OneFlow, parallelism is used as much as possible to achieve optimal distributed performance. For example, when considering the distributed training model of gradient synchronization, the transmission bandwidth between device memory and host memory is higher than the network transmission bandwidth between machines. OneFlow will perform two-level scatter and gather operations (local and between each machine) to increase locality and improve overall performance.
Give another example, when OneFlow is running, the control part of user program (usually is Python) is executed in parallel with the execution graph. When necessary, OneFlow use mutually exclusive section ensure the correctness of the concurrent execution.
Whether the data loader reads data from disk or is fed data from python, OneFlow ensures that it uses parallelism whenever possible, so that the computing device will not be idle due to waiting for data.
If existing frameworks want to overlap data movement and computation as much as possible, they usually use multiple nested callback functions. When there are too many nesting levels, the so-called Callback Hell becomes troublesome, and the correctness and readability of code may decrease. However, in OneFlow, the above concurrency is implemented with the simple and clear Actor mechanism, which avoids the Callback Hell problem.
In addition, in the multi-machine network communication, the network communication library in OneFlow not only supports the low level epoll implementation, but also naturally supports high-performance communication protocol such as RDMA. However, in most other deep learning frameworks, they use RPC for data movement in the multi-machine network communication.
Compile-time based on a formal description of parallelism¶
OneFlow may be the most user-friendly deep learning framework that supports data parallelism, model parallelism, and pipelining parallelism in distributed scenarios. Users only need to create a network model as if it’s on a single device, and tell OneFlow which resource (machines and devices) is available. OneFlow will automatically generate an almost optimal execulation plan for the job, enabling the runtime system use these machines and devices in an efficient way.
This stems from a unique design of OneFlow: Consistent View. For multi-machines and multi-devices, OneFlow will abstract it into a single super large device , which we call a logical device. The device memory of this logical device is the sum of the actual device memories of multiple physical devices, and the computing power of this logical device is also the sum of the actual computing power of multiple physical devices.
The user only needs to define how the deep learning model is constructed in this logical super device, and doesn’t need to worry about how OneFlow maps from the model to the physical devices.
Here are two concepts: "logical" and "physical". "Logical" means that OneFlow abstracts the distributed computation and data into a single super-device, and "physical" means that the computation and data are actually deployed on various machines and devices.
The deep learning model is a computation graph composed of Ops, and each Op produces and consumes some data in the form of tensor. In a multi-machine and multi-devices environment, a logical Op is mapped to multiple physical Ops. The computation actually performed by each physical Op is a part of the logical Op computation, and a logical Tensor also is mapped to multiple physical Tensors, and each physical Tensor is a part of the logical Tensor.
In distributed training defined by other frameworks, each device is viewed as a "world", and the data or parameters are synchronized between multiple devices according to the exposed interface; In OneFlow, the involved multiple machines and multiple devices are together viewed as a "world". In the following, we introduce a set of Placement+SBP method for overall management of the world.
Placement¶
While creating the computation graph, each computation Op can be assigned an attribute called Placement, indicating on which machines and devices the logical Op will be deployed. In general data parallelism, all Ops are deployed on all devices. However, OneFlow also supports user-specified Op Placement. For example, if the network is too large for a single device to accommodate at all, OneFlow allows the first part of the network to be on one device and the second part on the other device. The devices work together like in a "relay game", which enables pipelining parallelism.
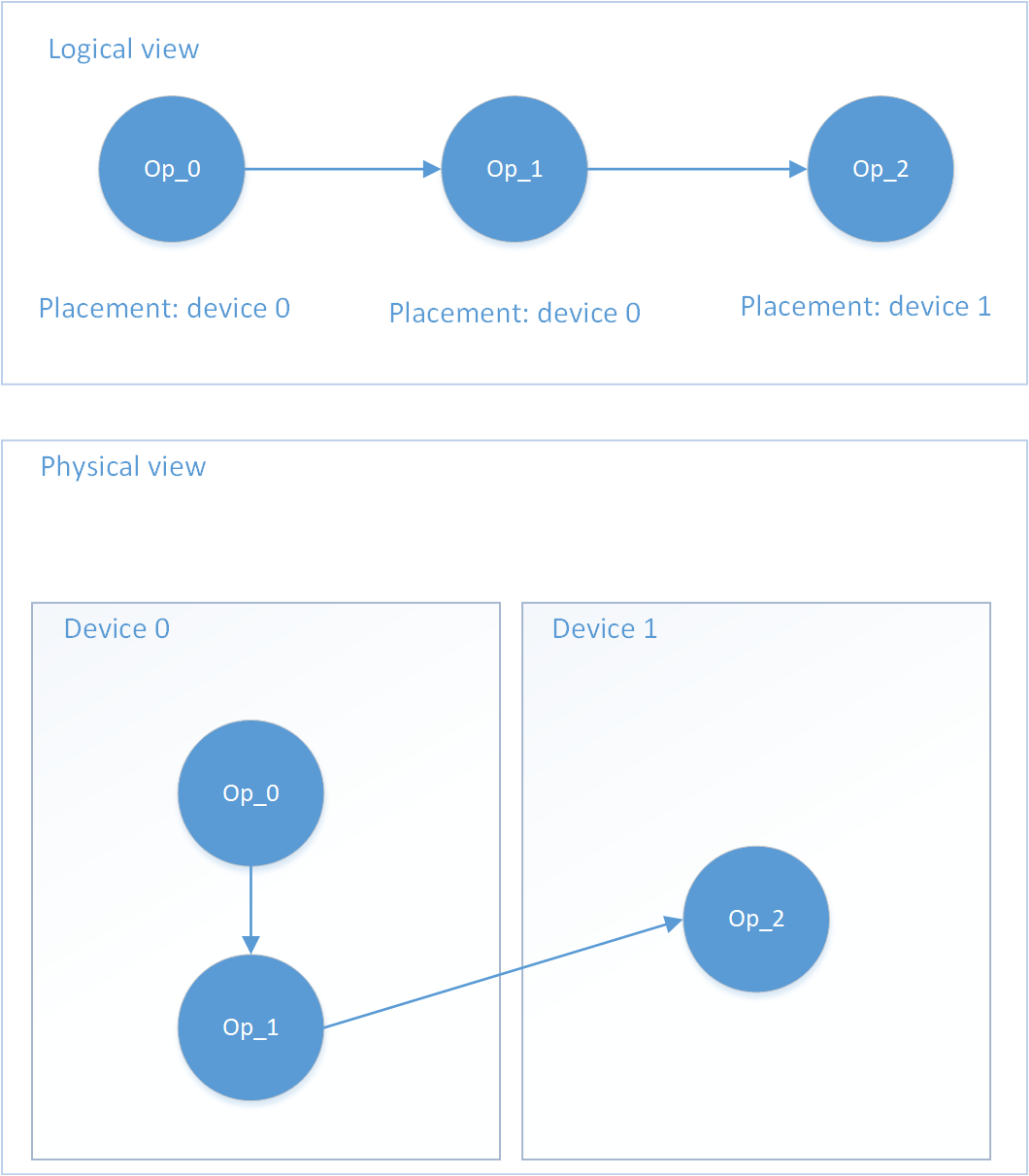
Figure 4 shows an example of a possible Placement. The user defines a network consisting of 3 Ops: Op_0 -> Op_1 -> Op_2.
In this example, the Placement of Op_0 and Op_1 is Device 0, and the Placement of Op_2 is Device 1. This is an example of pipelining parallelism. Oneflow will automatically insert the Copy Op needed for data transfer between Op_1 and Op_2.
SBP¶
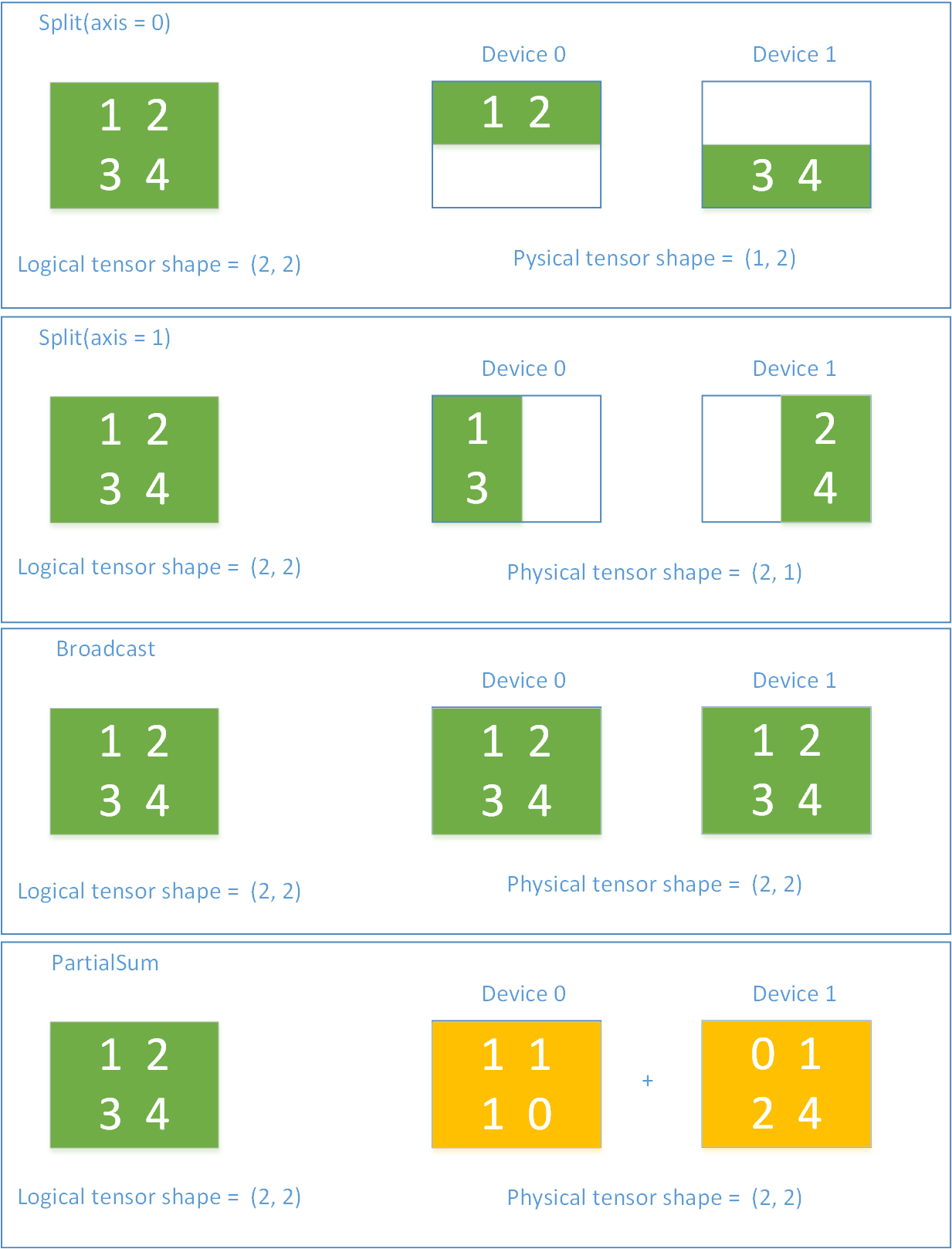
SBP is a unique concept of OneFlow. It is a combination of the initials of three words: Split, Broadcast, PartialSum (taking PartialSum as an example, in fact, it can also be a reduce operation such as PartialMin, PartialMax). The full name of SBP is SbpParallel, which represents a mapping relationship between the logic Tensor and the physical Tensor.
Split means that the physical Tensor is obtained by splitting the logical Tensor along a certain dimension. An axis parameter is used to indicate the dimension of the split. If multiple physical Tensors are concatenated along the dimension of Split, the logical Tensor can be restored.
Broadcast indicates that each physical Tensor is exactly a copy of the logical Tensor.
PartialSum indicates that although the physical Tensor has the same shape as the logical Tensor, the value in the physical Tensor is a part of the value in the corresponding position in the logical Tensor, if you add multiple physical Tensors at the same positions, you can restore the logical Tensor.
Figure 5 shows a simple example of SbpParallel.
SbpSignature is a collection of SbpParallels, each of which is an attribute of a specific Op. It depicts how a logical Op is mapped to multiple physical Ops on each device, and how these physical Ops treat the logical and physical mapping of their Input and Output Tensors. An Op may have multiple legal SbpSignatures. A simple legal signature is that the SbpParallel values of both input and output are Broadcast, which means that each physical Op needs the entire logical Tensor.
Once the logical computation graph is constructed by the user, OneFlow generates a distributed physical execution graph by the Compiler. Among the feasible Placements of Ops and the list of legal SbpSignature of each Op, the Compile is able to find an optimal SbpSignature (such as with he minimum transmission cost) for each Op, so that the Compiler can generate the most efficient execution plan.
Regarding to the list of legal SbpSignatures of an Op, we will give an example of an Op of matrix multiplication (matmul).
Definition: Y = matmul(A,B), A, B, Y are all Tensor, which means Y = AB. Then there are at least two legal SbpSignatures:
-
1) Y:
Split(0), A:Split(0), B:Broadcast -
2) Y:
Split(1), A:Broadcast, B:Split(1)
The diagram of the two legal signatures on the two devices is shown in Figure 6. Assume that the shapes of the logical input and output Tensor of MatMul is:
A(64, 10) × B(10, 50) -> Y(64, 50)
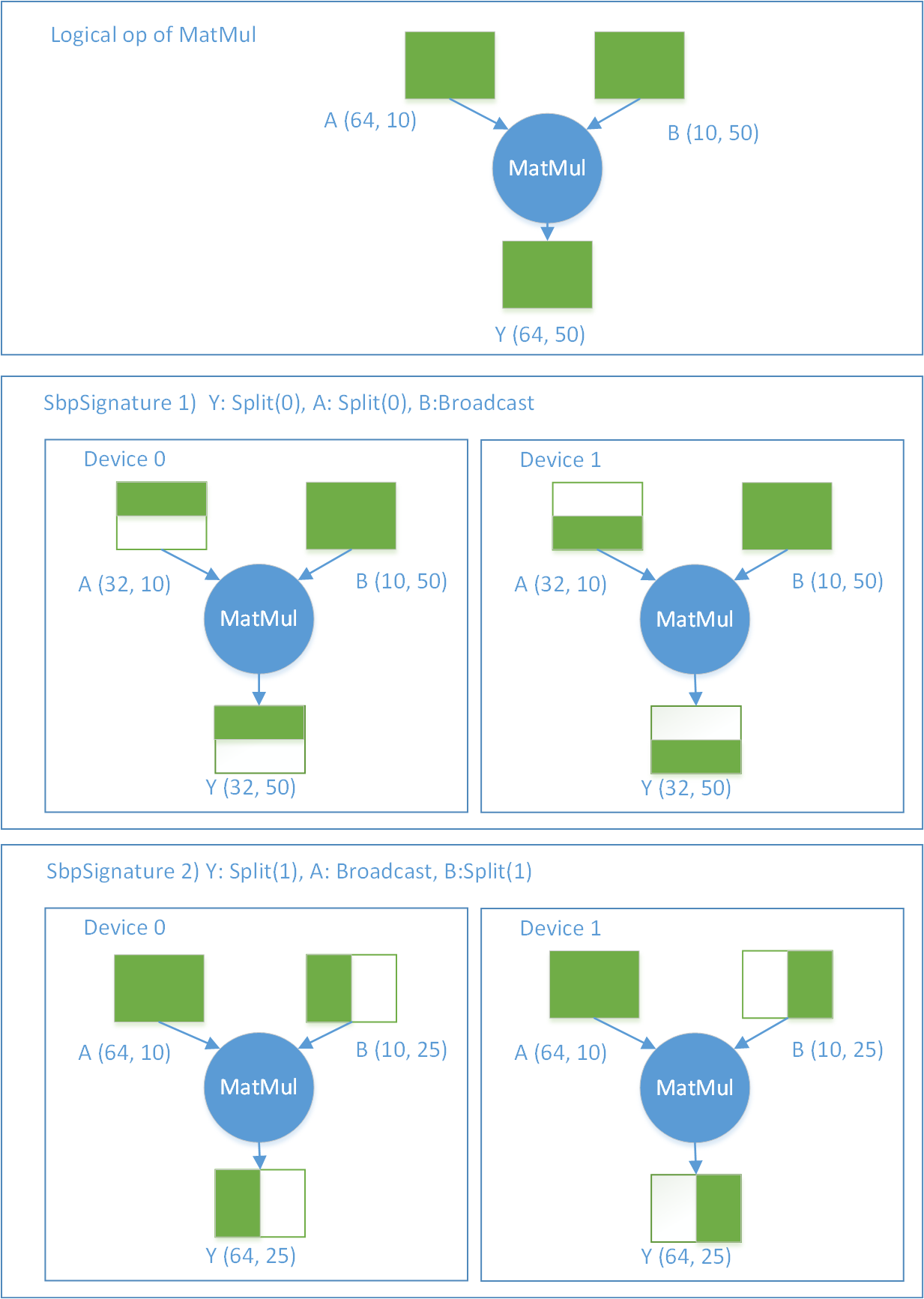
, and the Op is distributed on two devices. Under the first SbpSignature, A on device 0 is the first half of logical A, A on device 1 is the second half of logical A (division along the 0th dimension), and B on both devices is exactly the same as the logical B. The output Y from the two devices is the first half and the second half of the logical Y respectively. The second SbpSignature can also be analyzed in the same way.
It should be noted that when A is data and B is model, the first SbpSignature is actually data parallelism , and the second SbpSignature is model parallelism . If there’re two adjacent MatMul ops, the former uses the first SbpSignature and the latter uses the second SbpSignature, the entire network will form the so-called hybrid parallelism .
Figure 7 is an example of hybrid parallelism. It defines Y0 = MatMul_0(A0, B0), Y1 = MatMul_1(Y0, B1), a computation graph composed of two ops, where A0, Y0, Y1 are data Tensor, B0 , B1 is the model Tensor.
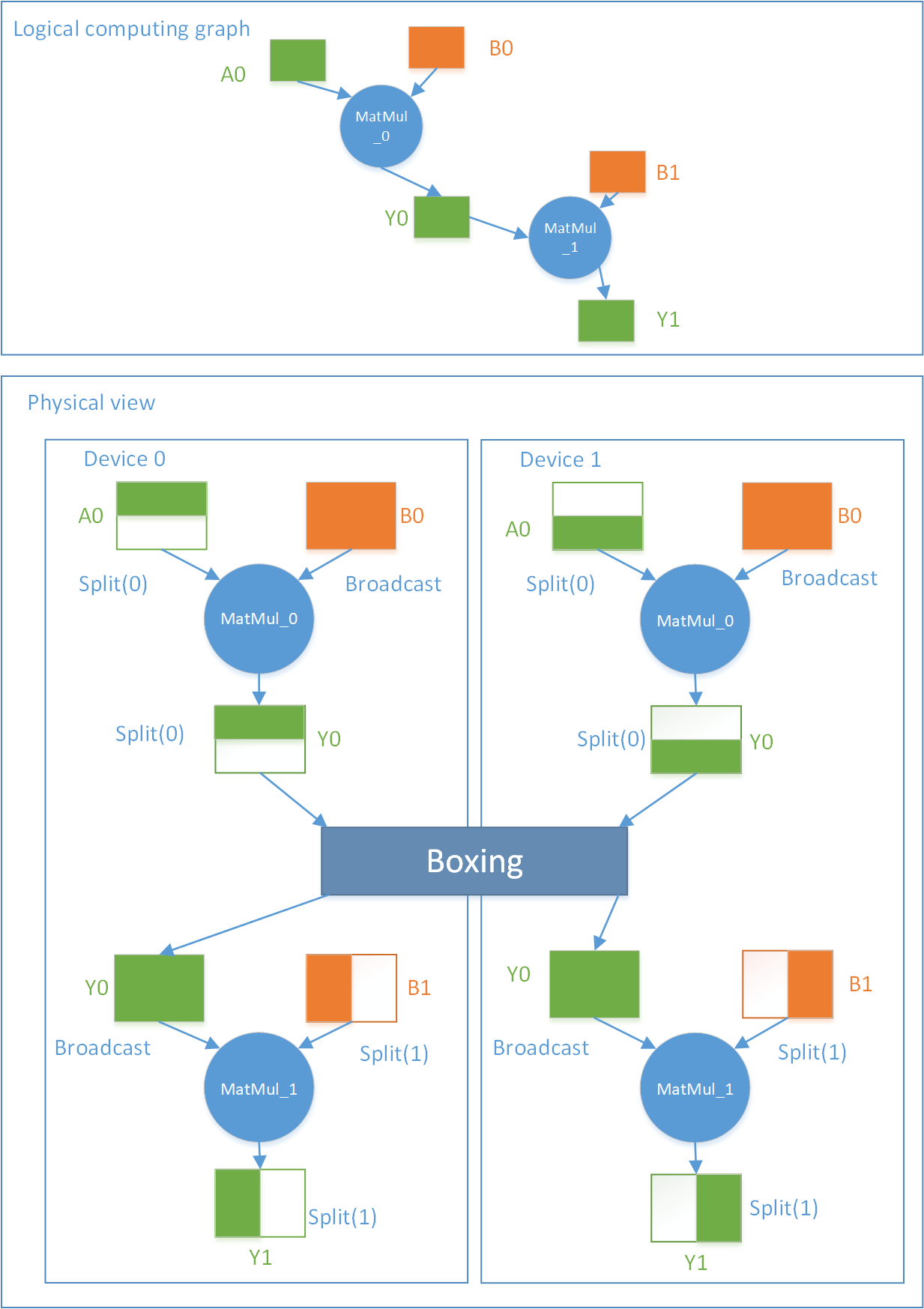
In Figure 7, Y0 produced by MatMul_0 is consumed by MatMul_1, but the two ops view the SBP of the same Tensor differently. MatMul_0 considers Y0 to be a Split (axis=0) segment, but MatMul_1 needs a Broadcast Y0 input. To achieve the mathematical consistency, OneFlow will automatically insert a "universal" Boxing Op to do the necessary data splitting, concatenating, handling and summing operations, so that all Ops can efficiently get the data they want in a distributed environment.
In data parallelism, if the Tensor in a training forward model is Broadcast, the corresponding gradient computation in the backward direction is PartialSum. When the Optimizer needs all the gradients to update the model, it will trigger the Boxing mechanism to perform efficient gradient synchronization.
The most user-friendly distributed framework¶
OneFlow’s Placement + SBP + Boxing mechanisms allow Op and Tensor in user-defined computation graphs to be distributed on various machines and devices in any way. No matter it is data parallelism, model parallelism or pipelining parallelism, for OneFlow, it is just a combination of a specific SbpSignature under a specific Placement, which can be easily configured by the user, or handed over to OneFlow for automatic processing.
In addition, before Microsoft launched the ZeRO-2 framework, OneFlow already supported similar features. In the multiple machines and multiple devices scenarios, each model Tensor is only saved on one of the devices, reducing the memory usage in gradient computations.
Summary¶
In summary, during the compile time, OneFlow introduces a mathematically rigorous formal system to describe all legal parallel modes, and enable the compiler to automatically search for the optimal parallel mode conveniently.
At the runtime, the Actor system supports parallel and concurrent execution in an flexible and efficient way. The core of OneFlow runtime system has the advantages of simplicity, efficiency and high scalability.
Based on such mechanisms, OneFlow makes the distributed training extremely efficient, and makes it as easy as training on a single device.