OneFlow 的并行特色¶
在 Consistent 与 Mirrored 视角中,我们已经知道 OneFlow 提供了 mirrored 与 consistent 两种看待分布式系统的视角,并且提前知道了 OneFlow 的 consistent 视角颇具特色。
因为在 consistent_view 下,OneFlow 提供了逻辑上统一的视角,分布式训练时,用户可以自由选择数据并行、模型并行还是是混合并行。
在本文中,继续深入介绍 OneFlow 独具特色的 consistent 视角,包括:
-
OneFlow 在
consistent_view下纯数据并行流程示意 -
OneFlow 在
consistent_view下混合并行流程示意 -
混合并行的优势及适用场景
-
OneFlow 混合并行实例
网络模型训练的逻辑图¶
我们先设定一个简单的多层网络,作为我们我们讨论并行方式的载体,其结构如下图所示:
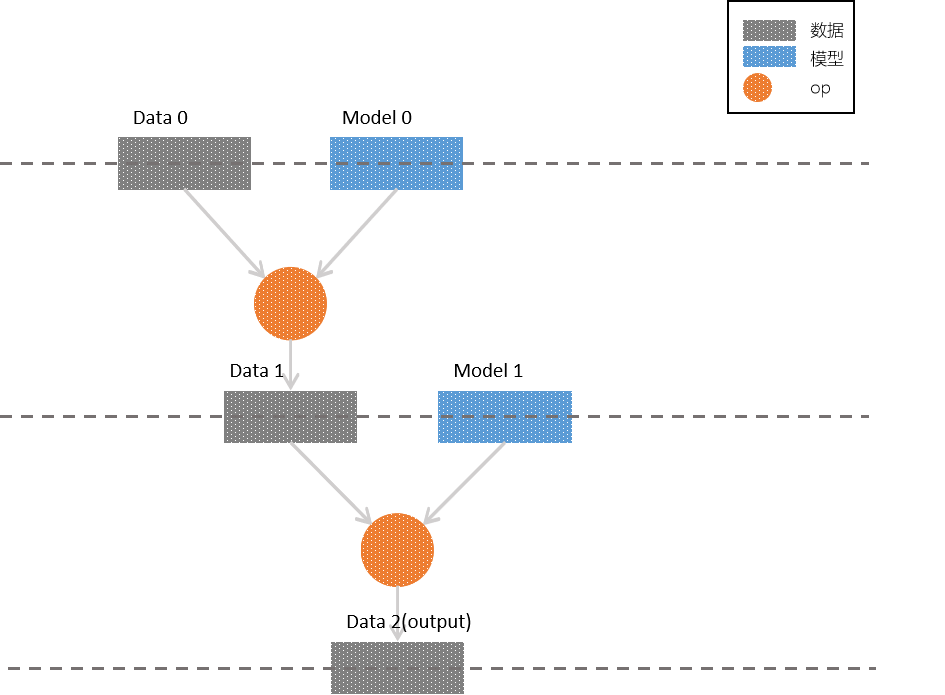
各层中,有 样本 (灰色矩形)、 模型 (蓝色矩形),以及作用在两者之上的 op (圆形),为了简化讨论,我们也可将样本与模型限定为 矩阵 ,作用在它们之上的op为 矩阵乘法 。
对照上图,我们很容易梳理出该网络模型的逻辑:
-
第0层的输入为
Data 0矩阵与Model 0矩阵,它们进行op(矩阵乘法)运算后,输出Data 1 -
第1层的输入为
Data 1矩阵与Model 1矩阵,它们进行op运算后,输出output -
第2层为
output层,Data 2作为整个网络的输出;当然,在更深的网络中,它也可以作为下一层的输入继续参与训练
consistent 视角下支持数据并行、模型并行与混合并行,我们将依次进行介绍,其中混合并行是重点。
Consistent 视角下的并行特色¶
纯数据并行¶
我们已经知道,consistent 视角下,默认的并行方式是数据并行;而如果选择 mirrored 视角,则只能采用数据并行;若在调用作业函数时直接传递 numpy 数据(而不是使用 OneFlow 的 DataLoader 及相关算子),两者的区别在于:
-
mirrored 视角下,采用纯数据并行,需要自己根据参与训练的卡数对数据进行切分、重组,使用
list传递和接收数据; -
而 consistent 视角下提供了逻辑上的统一看待,数据的切分和重组交给了 OneFlow 框架完成。
下图是 consistent 视角下,采用纯数据并行的方式,实现原逻辑网络模型的流程示意图:
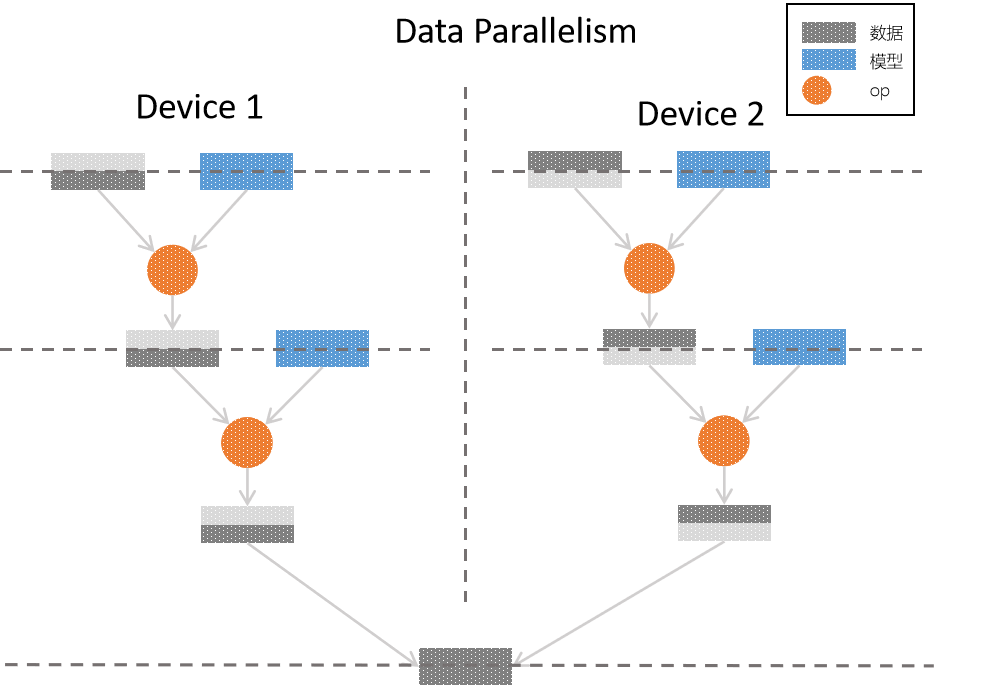
在纯数据并行中,采用了2张显卡进行并行训练,因为采用了 纯数据并行 ,可以看到,对于原逻辑模型中的每一层,样本数据都被平均分配到了各个卡上,每张卡上都拥有 完整的模型,与切分的数据进行 op 运算,最后组合各个卡上的样本,得到完整的输出。
纯模型并行¶
在 consistent 视角下,也可以通过选择纯模型并行(设置方式在下文实例中会介绍),其流程示意图为:
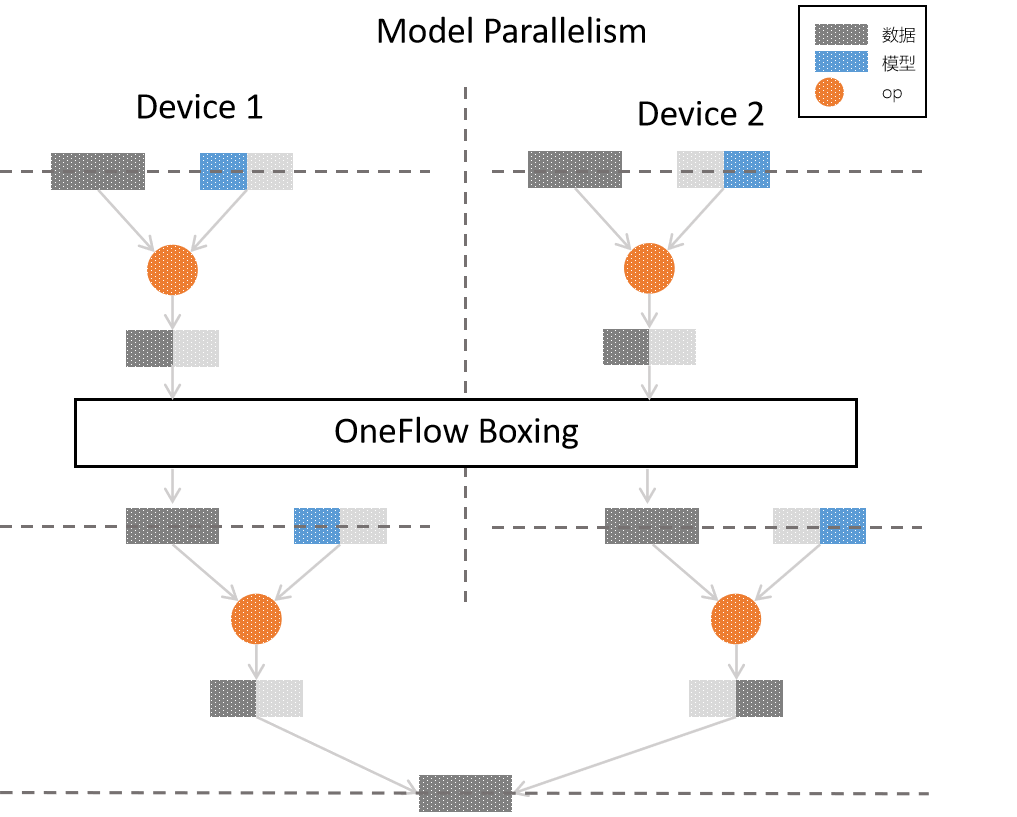
在纯模型并行中,同样是2张显卡进行并行训练,原逻辑模型中的每一层中,都是 部分模型 与 完整的数据 进行 op 运算,最后组合得到完整的输出。
值得一提的是,从上图可以看出,各个卡上第0层的输出,并 不能 直接作为第1层的输入:因为模型并行中,为完成 op 操作,需要部分的模型与 完整的 数据; 为了解决这个问题,OneFlow 中使用了 boxing 机制。
boxing 机制会统筹分布式训练中各个节点的数据,并合理切分、合并到对应的卡上,除了模型并行过程中的数据重组问题外,数据并行中的反向梯度同步,也使用 boxing 机制解决。
boxing 的内部机制虽然复杂,但是对于用户而言是透明的,我们仅仅是防止读者产生迷惑才加入了 boxing 的图示,对于本文而言,我们只需要了解:OneFlow 会自动协调好分布式中数据的同步问题。
选择最优的并行方式¶
数据并行与模型并行的优劣并不是一成不变的,样本规模、模型规模及模型结构决定了分布式训练中的综合表现,需要具体情况具体分析。
概括而言:
-
数据并行情况下,需要同步的信息是反向传播过程的 梯度,因此应该确保各个训练节点之间的信息同步速度要比节点内部的计算速度快,比如说 卷积层 的参数较少,但是计算量大,就比较适合使用数据并行;
-
模型并行情况下,因为可以将逻辑上作为整体的模型 切分到各个物理卡 上,能够解决“模型太大,一张卡装不下”的问题,因此,对于参数量大的神经网络层(如最后的全连接层),可以考虑使用模型并行。
实际上,也可以使用 混合并行,在同一个分布式训练的不同部分,组合使用数据并行、模型并行。比如,对于神经网络中靠前的参数较少、计算量大的层,采用数据并行;在最终的参数众多的全连接层,则采用模型并行,以下是针对本文最开始的网络模型逻辑图的 混合并行 实现方案的示意图:
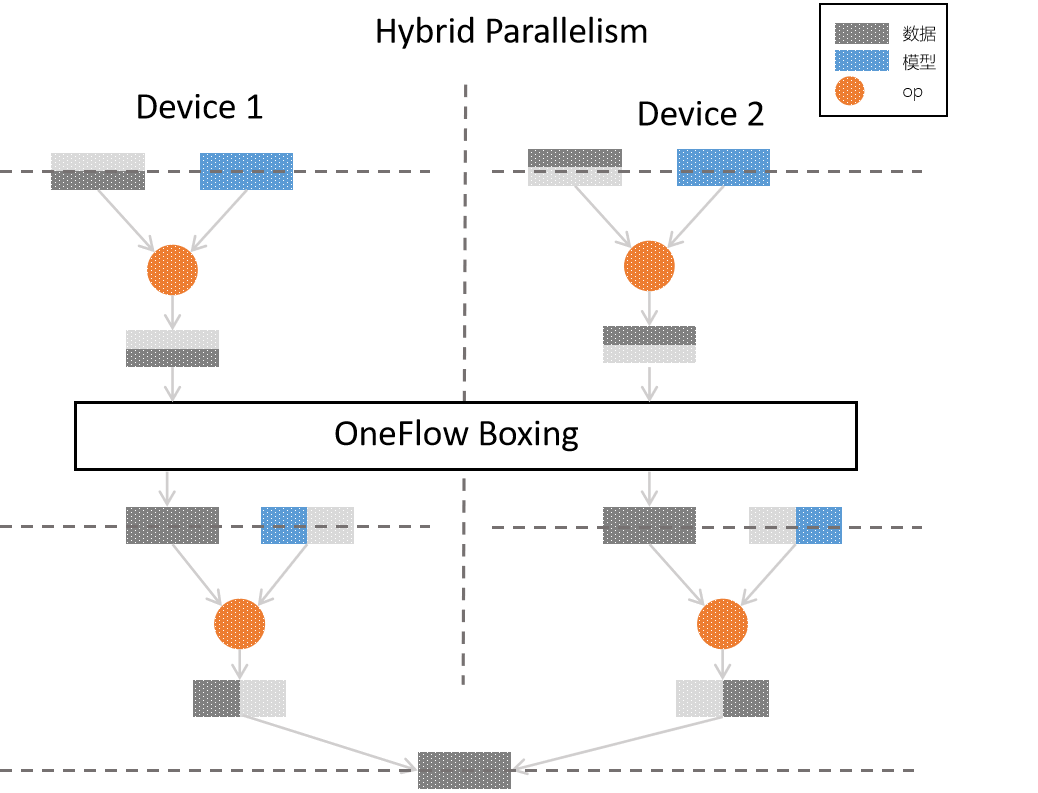
目前,其它的主流框架对于混合并行或者不支持,或者需要深度定制,而 OneFlow 中可以通过简单的设置,配置混合并行的分布式训练,还可以用自由度超高的流水并行,深度优化分布式系统。
混合并行实例¶
代码¶
以下脚本,在 consistent 视角下,我们对 MLP 模型采用了混合并行方案:输入层与隐藏层采用(默认的)数据并行;输出层采用模型并行并进行列切分。
更具体的解析在后文“代码解读”可见。
代码解读¶
以上脚本修改自3分钟快速上手中的示例代码,比较两份代码,也可以体会到在 OneFlow 的 consistent_view 下进行各种并行方案的配置是多么的简单,只需要在单机的程序上稍加修改即可。
以上程序的关键部分有:
-
通过
oneflow.config.gpu_device_num接口设置参与训练的GPU数目:flow.config.gpu_device_num(2) -
reshape及hidden采用默认的数据并行,不需要修改;输出层通过设置model_distribute为flow.distribute.split(axis=0)变为模型并行:有读者可能好奇为什么def mlp(data): initializer = flow.truncated_normal(0.1) reshape = flow.reshape(data, [data.shape[0], -1]) hidden = flow.layers.dense( reshape, 512, activation=flow.nn.relu, kernel_initializer=initializer, name="dense1", ) return flow.layers.dense( hidden, 10, kernel_initializer=initializer, # dense为列存储,进行split(0)切分 model_distribute=flow.distribute.split(axis=0), name="dense2", )split(axis=0)是列切分?需要说明的是,OneFlow 中的dense内部采用列存储,因此以上代码的flow.distribute.split(axis=0)确实是在做列切分。
此外,flow.layers.dense 使用 model_distribute 形参设置并行方式,其内部调用了底层更通用的 get_variable 接口创建 blob, get_variable 接口设置并行方式的形参名为 distribute。
可以看到,我们通过极少量的修改,就能将单机训练程序改为分布式、混合并行的程序,这是 OneFlow 区别于其它框架的一大特色。
流水并行实例¶
在模型并行之外,OneFlow 还提供了一种灵活度更高的“流水并行”的并行方式,可以让用户使用 scope.placement 接口显式指定用来运行逻辑 op的 物理硬件。
在流水并行中,整个神经网络有的层次在一组物理设备上,另外一些层次在另外一组物理设备上,它们以接力的方式协同工作,分多个阶段,在设备之间流水执行。
在以下示例中,我们对 Consistent 与 Mirrored 视角中的“在 OneFlow 中使用 consistent 视角”代码进行简单修改,展示了流水并行模式。
代码¶
完整代码:hybrid_parallelism_lenet.py
更详细的讨论可见后文的“代码解读”。
代码解读¶
以上关键的代码只有2行,且他们的本质作用是类似的:
-
通过
oneflow.scope.placement,指定hidden层的 op 计算运行在0号 GPU 上with flow.scope.placement("gpu", "0:0"): hidden = flow.layers.dense( reshape, 512, activation=flow.nn.relu, kernel_initializer=initializer, name="hidden", ) -
通过
oneflow.scope.placement,指定output层的op计算运行在第0号主机的1号 GPU 上with flow.scope.placement("gpu", "0:1"): output = flow.layers.dense( hidden, 10, kernel_initializer=initializer, name="outlayer" )
scope.placement 的具体使用,可参阅 API 文档。
流水并行,使得用户可以为每个 op 指定物理设备,非常适合对网络模型及分布式情况都很熟悉的用户进行 深度优化 。
此外,OneFlow 提供的 API oneflow.unpack、oneflow.pack 等,结合了 OneFlow 自身任务调度的特点,使得流水并行更易用、高效,我们将在另外的文章中专门介绍。