Consistent 与 Mirrored 视角¶
在进行分布式训练时,OneFlow 框架提供了两种角度看待数据与模型的关系,被称作 consistent 视角与 mirrored 视角。
本文将介绍:
-
数据并行与模型并行的区别及适用场景
-
在分布式任务中采用
mirrored视角及其特点 -
在分布式任务中采用
consistent视角及其特点
数据并行与模型并行¶
为了更好地理解 OneFlow 中的 consistent 和 mirrored 视角,我们需要了解分布式任务中的 数据并行 、模型并行 两种并行方式的区别。
为了更直观地展示两者的差别,我们先看一个简单的 Op :矩阵乘法。
我们假定在模型训练中,存在一个输入矩阵 I ,通过矩阵 I 与矩阵 W 做矩阵乘法,得到输出矩阵 O 。

如以上所示,I的大小为(N, C1),W的大小为(C1, C2),O的大小为(N, C2)。
结合机器学习的业务逻辑,可以赋予以上几个矩阵直观意义:
-
I 矩阵作为输入矩阵,每一行都是一个样本,一行中的各列代表了样本的特征
-
W 矩阵代表了模型参数
-
O 是预测结果或者 label ,如果是预测作业,那么就是由 I、W 求解 O,得到分类结果的过程;如果是训练作业,那么就是由 I 与 O 求解 W 的过程
当以上 I 矩阵的行 N 很大,说明样本很多;如果 W 矩阵的列 C2 很大,说明模型复杂;当样本数目、模型复杂程度复杂到一定程度时,单机单卡的硬件条件已经无法承载训练作业,就需要考虑分布式的方式训练。而在分布式系统中,我们可以选择 数据并行 和 模型并行。
为了便于理解数据并行与模型并行,我们先用下图作为矩阵相乘 Op 的示例:

等式左边第1个灰色的矩阵代表输入样本,每一行是一个样本;等式左边第2个蓝色的矩阵代表模型。
在后文中,我们将看到以上的 op,在数据并行与模型并行下,不同的“切分”方式。
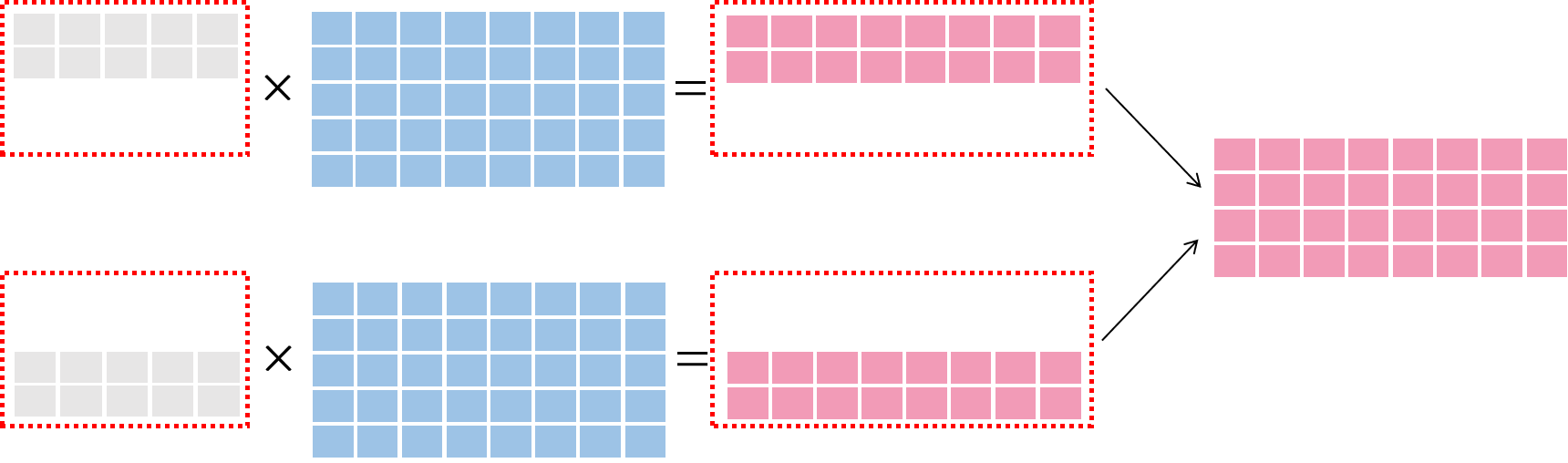
数据并行图示¶
在 数据并行 中,将样本数据进行切分,切分后的数据 被送至各个训练节点,与 完整的模型 进行运算,最后将多个节点的信息进行合并,如下图所示:
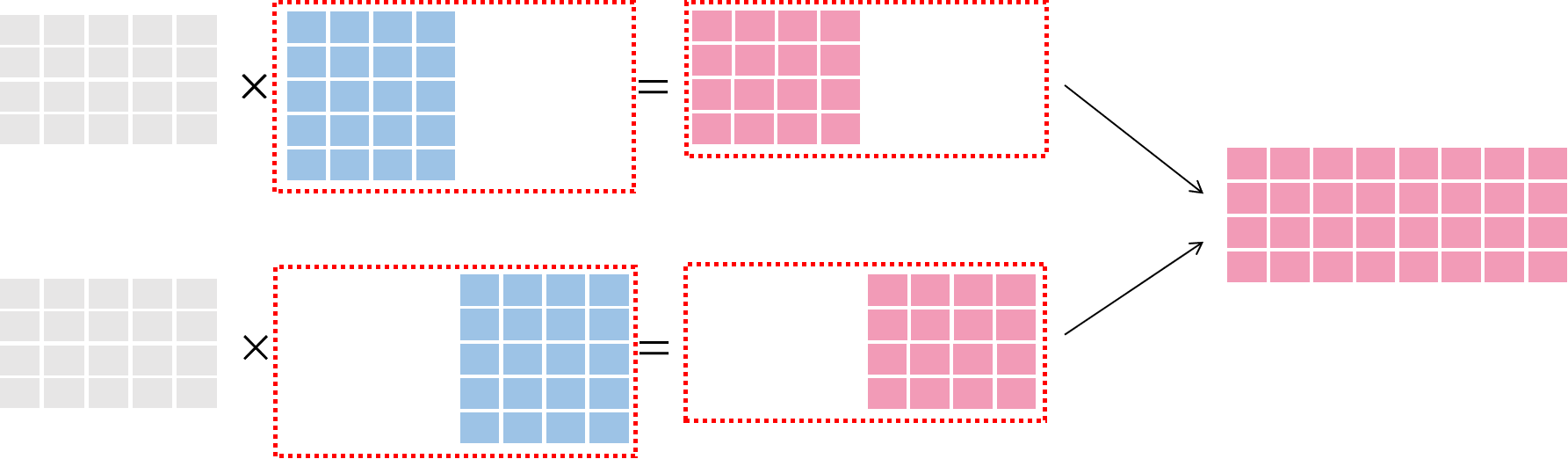
模型并行图示¶
在 模型并行 中,将模型进行切分,完整的数据 被送至各个训练节点,与 切分后的模型 进行运算,最后将多个节点的运算结果合并,如下图所示:
总之:
-
数据并行下,各个训练节点的模型是完全一样的,数据被切分;
-
模型并行下,各个训练节点都接收一样的完整数据, 模型被切分。
接下来我们将介绍 OneFlow 看待分布式系统的两种视角(mirrored 视角与 consistent 视角),学习在不同的视角下如何选择并行方式。
两类占位符¶
在使用OneFlow搭建神经网络及定义与调用作业函数中已经介绍了 数据占位符 与 Blob 的概念。
实际上,针对并行,OneFlow的数据占位符还可以细分为 两类:分别通过接口 oneflow.typing.Numpy.Placeholder 和 oneflow.typing.ListNumpy.Placeholder 构造的占位符,分别对应 Consistent 与 Mirrored情况。
我们将在下文中看到它们的具体应用。
在 OneFlow 中使用 mirrored 视角¶
其它的框架,如 TensorFlow、Pytorch 均支持 mirroed view;OneFlow 的 mirrored 视角与它们类似。
在 mirrored 视角下,模型被镜像复制到每张卡上,每个节点的模型构图是完全相同的,只能采用 数据并行 。
在 OneFlow 中,默认不是 mirrored 策略,需要通过 flow.function_config() 的 default_logical_view 接口来显式指定:
func_config = flow.function_config()
func_config.default_logical_view(flow.scope.mirrored_view())
在 mirrored_view 下,只能采用 数据并行 的并行模式,在调用作业函数时,我们需要将数据按照训练节点的数目(显卡总数)进行平均切分,并将切分后的数据放入 list 中进行传递,list 中的每个元素,就是后分配给 各个显卡 的实际数据。
训练函数的返回值类型,也变作了 oneflow.typing.ListNumpy,是一个 list, list 中的每个元素,对应了每张卡上训练结果。
以上提及的 list 中的所有元素 拼接在一起 ,才是一个完整的 BATCH。而OneFlow会自动执行这个拼接的过程,无需用户进行多余的操作。
代码¶
在以下的脚本中,我们使用采用 mirrored_view 视角,使用2个 GPU 进行训练。
重点部分的说明请见后文“代码解析”部分。
代码解读¶
以上代码中:
- 使用
flow.config.gpu_device_num设置 GPU 数目为2
flow.config.gpu_device_num(2)
-
oneflow.typing.ListNumpy.Placeholder定义的样本数目,是被切分后的数目,即代码中的BATCH_SIZE_PER_GPU与总样本数BATCH_SIZE的关系为:BATCH_SIZE=BATCH_SIZE_PER_GPU×GPU_NUMdef train_job( images: tp.ListNumpy.Placeholder((BATCH_SIZE_PER_GPU, 1, 28, 28), dtype=flow.float), labels: tp.ListNumpy.Placeholder((BATCH_SIZE_PER_GPU,), dtype=flow.int32), ) -> tp.ListNumpy: -
切分后的数据,需要保存至
list中传入训练函数;list中元素的个数与 参与训练的GPU数目 一致;OneFlow 将按照list中元素顺序,向各卡传递数据(list中第 i 个元素对应第 i 张卡):images1 = images[:BATCH_SIZE_PER_GPU] images2 = images[BATCH_SIZE_PER_GPU:] labels1 = labels[:BATCH_SIZE_PER_GPU] labels2 = labels[BATCH_SIZE_PER_GPU:] imgs_list = [images1, images2] labels_list = [labels1, labels2] loss = np.array(train_job(imgs_list, labels_list)) -
返回的得到的结果
loss,是一个list。正常情况下,该list中元素个数应与 参与训练的GPU数目 一致;list中的第i个元素对应了第 i 张 GPU 卡上的运算结果。但由于OneFlow会在后台自动执行拼接操作,我们无需再在代码中进行多余的拼接步骤。只需将loss合并后进行计算并打印其平均值。total_loss = np.array([*loss[0], *loss[1]]) if i % 20 == 0: print(loss.mean())
在 OneFlow 中使用 consistent 视角¶
我们已经了解了 mirrored 视角,知道在 mirrored_view 视角下,样本会被平均分配到多个完全一样的模型上进行分布式训练,各个训练节点上的结果,需要组装才能得到真正完整的 BATCH,对应了逻辑上的 op 与 Blob。
除了 mirrored 视角外,OneFlow 还提供了 consistent 视角。consistent 视角是 OneFlow 的一大特色,与 mirrored 视角相比有很大的优势。
默认情况下 OneFlow 采取的是 consistent 视角,如果想显式声明,也可以通过代码设置:
config = flow.function_config()
config.default_logical_view(flow.scope.consistent_view())
之所以说 consistent 视角是 OneFlow 的一大特色,是因为在 OneFlow 的设计中,若采用 consistent_view,那么从用户的视角看,分布式系统中的多个设备将获得 逻辑上的统一,同样以本文开头的矩阵乘法为例,我们只需要关注矩阵乘法本身数学计算上的意义;而在工程上到底如何配置、采用模型并行还是数据并行等细节问题,可以使用 OneFlow 的接口轻松完成。OneFlow 内部会高效可靠地解决 数据并行中的数据切分 、模型并行中的模型切分 、串行逻辑 等问题。
在 OneFlow 的 consistent 视角下,可以自由选择模型并行、数据并行、流水并行或者混合并行。
代码¶
以下脚本,我们采用 consistent 视角,使用2个 GPU 进行训练,consistent 策略下默认的并行方式仍然是 数据并行。关于如何在 consistent 策略下设置 模型并行 及 混合并行 不在本文讨论范围,我们在OneFlow 的并行特色中有专门的介绍与示例。
代码中的重点将在下文介绍。
代码解读¶
以上代码中:
-
使用
flow.config.gpu_device_num设置GPU数目:flow.config.gpu_device_num(2) -
使用
tp.Numpy.Placeholder定义 consistent 视角下的占位符,因为Numpy.Placeholder产出的 Blob 代表逻辑上的 op 及数据占位符,因此此处的 BATCH_SIZE 就是整个分布式训练的样本总和,不需要人为切分或者组合@flow.global_function(type="train") def train_job( images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float), labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32), ) -> tp.Numpy: -
调用作业函数,直接得到训练结果,训练结果已经由 OneFlow 完成分布式过程中切分与合并的工作。在 consistent 视角下,多卡的分布式训练与单卡的训练,代码差别极少,上手体验几乎一样
for i, (images, labels) in enumerate(zip(train_images, train_labels)): loss = train_job(images, labels) if i % 20 == 0: print(loss.mean())
扩展¶
随着机器学习理论与实践发展,现在已经出现了很多单机无法训练的网络;也出现了越来越多仅采用数据并行无法很好完成训练的模型。
采用 OneFlow 的 consistent 视角,通过自由选择及组合并行方式,可以很好地解决以上问题,我们在 OneFlow 的并行特色进行了专门的介绍。