2D SBP¶
阅读 集群的全局视角 和 Global Tensor 之后,相信你已经掌握了 SBP 和 SBP Signature 的基本概念,并且能够上手相关的编程任务。实际上,以上资料中涉及都是 1D SBP。
本文将在读者掌握 1D SBP 的基础上,介绍 2D SBP,它能够更灵活地应对更复杂的分布式训练场景。
2D 设备阵列¶
我们已经熟悉 1D SBP 的 placement 配置,在 1D SBP 的场景下,通过 oneflow.placement 接口配置集群,比如使用集群中的第 0~3 号 GPU 显卡:
>>> placement1 = flow.placement("cuda", ranks=[0, 1, 2, 3])
以上的 "cuda" 指定了设备类型,ranks=[0, 1, 2, 3] 指定了集群中的计算设备。其实,ranks 不仅可以是一维的int list,还可以是多维的int数组:
placement2 = flow.placement("cuda", ranks=[[0, 1], [2, 3]])
当 ranks 是 ranks=[0, 1, 2, 3] 这种一维list的形式时,集群中的所有设备组成了一个 1D 设备向量,这也是 1D SBP 名称的由来。
当 ranks 是多维数组的形式时,集群中的设备被分组为一个多维的设备阵列。ranks=[[0, 1], [2, 3]] 表示集群中的四个计算设备被划分为了 \(2 \times 2\) 的设备阵列。
2D SBP¶
我们已经知道,构造 Global Tensor 时,需要同时指定 placement 与 SBP。当 placement 中的集群是 2 维的设备阵列时;SBP 也必须与之对应,是一个长度为 2 的 tuple,这个tuple中的第 0 个、第 1 个 元素,分别描述了 Global Tensor 张量在设备阵列第 0 维、第 1 维的分布。
比如,以下代码,配置了 \(2 \times 2\) 的设备阵列,并且设置 2D SBP 为 (broadcast, split(0))。
>>> a = flow.Tensor([[1,2],[3,4]])
>>> placement = flow.placement("cuda", ranks=[[0, 1], [2, 3]])
>>> sbp = (flow.sbp.broadcast, flow.sbp.split(0))
>>> a_to_global = a.to_global(placement=placement, sbp=sbp)
它意味着,逻辑上的数据,在整个设备阵列上,在第 0 维度(“竖着看”)做 broadcast;在第 1 维度(“横着看”)做 split(0)。
我们通过下图做阐述:
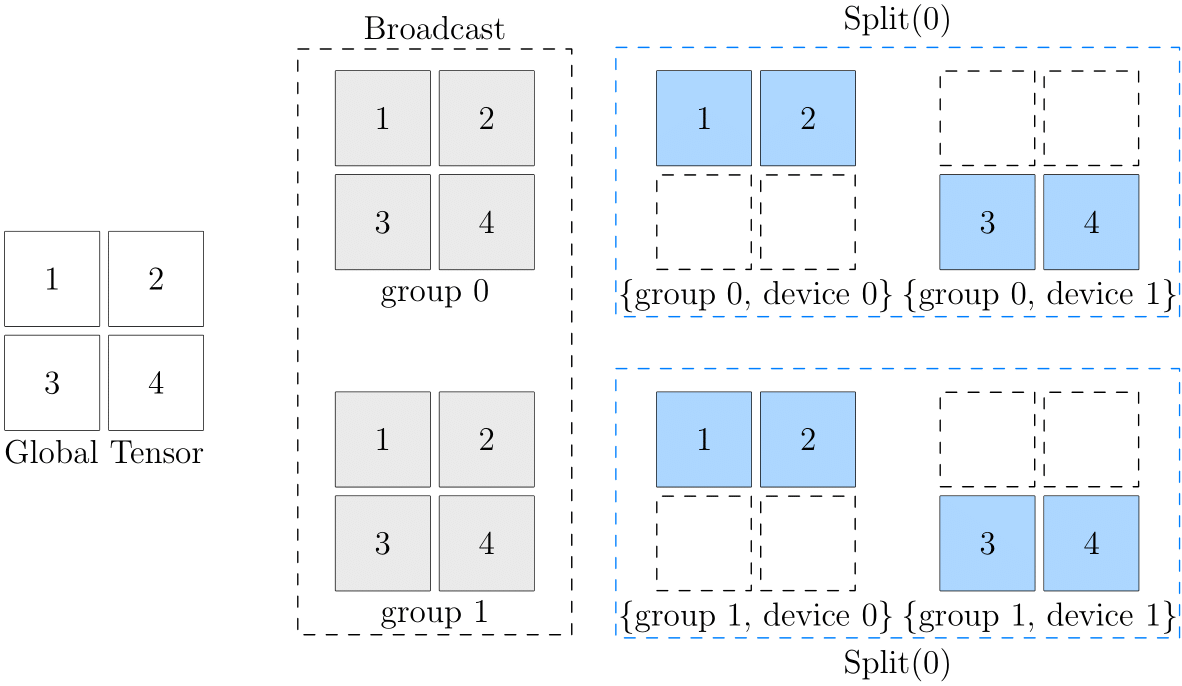
此图的最左边是全局视角的数据,最右边是设备阵列上各个设备的数据。可以看到,从第 0 维的角度看,它们都是 broadcast 的关系:
- (group0, device0) 与 (group1, device0) 中数据一致,互为
broadcast关系 - (group0, device1) 与 (group1, device1) 中数据一致,互为
broadcast关系
而从第 1 维的角度看,它们都是 split(0) 的关系:
- (group0, device0) 与 (group0, device1) 互为
split(0)关系 - (group1, device0) 与 (group1, device1) 互为
split(0)关系
直接理解逻辑数据和最终的设备阵列中的物理数据对应关系可能有一定难度,大家在思考 2D SBP 时,可以假想一个中间状态(上图中灰色部分),以 (broadcast, split(0)) 为例:
- 原始逻辑张量,先经过
broadcast,广播到 2 个 group 上,得到中间的状态 - 在中间状态的基础上,继续在各自的 group 上,做
split(0),得到最终设备阵列中各个物理张量的状态
2D SBP Signature¶
类似 1D SBP 有 SBP Signature 的概念,算子也有 2D SBP Signature,在掌握了 1D SBP 及其 Signature 概念的基础上,2D SBP Signature 非常简单,只需要遵循一条原则:
- 在各自的维度上独立推导即可
我们以矩阵乘法为例,先回顾 1D SBP 的情况,假定有 \(x \times w = y\) 可以有以下的 SBP Signature:
以及
现在,假定我们给 \(x\) 设置了 2D SBP 为:\((broadcast, split(0))\), 给 \(w\) 设置 2D SBP 为 \((split(1), broadcast)\),那么,在 2D SBP 的背景下, \(x \times w = y\) 运算,得到 \(y\) 的 SBP 属性为 \((split(1), split(0))\)。
也就是说,以下几个 2D SBP,构成矩阵乘法的 2D SBP Signature:
2D SBP 使用示例¶
在本节中,我们将通过一个简单的例子演示如何使用 2D SBP 进行分布式训练。同上文中的例子,假设有一个 \(2 \times 2\) 的设备阵列,鉴于读者可能目前并没有多个 GPU 设备,我们将使用 CPU 来模拟 \(2 \times 2\) 设备阵列的情形,对输入张量采用上文图中 (broadcast, split(0)) 的并行策略。
首先,导入依赖:
import oneflow as flow
import oneflow.nn as nn
然后,定义要使用到的 placement 和 sbp:
PLACEMENT = flow.placement("cpu", [[0, 1], [2, 3]])
BROADCAST = (flow.sbp.broadcast, flow.sbp.broadcast)
BS0 = (flow.sbp.broadcast, flow.sbp.split(0))
PLACEMENT 的 ranks 参数是一个二维 list,代表将集群中的设备划分成 \(2 \times 2\) 的设备阵列。如前文所述,SBP 需要与其对应,指定为长度为 2 的 tuple。其中,BROADCAST 表示在设备阵列的第 0 维和第 1 维都进行广播,BS0 的含义与前文的描述相同。
假设我们有以下模型:
model = nn.Sequential(nn.Linear(8, 4),
nn.ReLU(),
nn.Linear(4, 2))
model = model.to_global(placement=PLACEMENT, sbp=BROADCAST)
然后构造数据并进行前向推理:
x = flow.randn(1, 2, 8)
global_x = x.to_global(placement=PLACEMENT, sbp=BS0)
pred = model(global_x)
(1, 2, 8) 的 local tensor,然后通过 Tensor.to_global 方法获取对应的 global tensor,最后将其输入到模型中进行推理。
通过 Tensor.to_local 方法获取当前物理设备上的 local tensor 后,我们可以通过输出其形状和值来验证数据是否被正确处理:
local_x = global_x.to_local()
print(f'{local_x.device}, {local_x.shape}, \n{local_x}')
cpu:2, oneflow.Size([1, 2, 8]),
tensor([[[ 0.6068, 0.1986, -0.6363, -0.5572, -0.2388, 1.1607, -0.7186, 1.2161],
[-0.1632, -1.5293, -0.6637, -1.0219, 0.1464, 1.1574, -0.0811, -1.6568]]], dtype=oneflow.float32)
cpu:3, oneflow.Size([1, 2, 8]),
tensor([[[-0.7676, 0.4519, -0.8810, 0.5648, 1.5428, 0.5752, 0.2466, -0.7708],
[-1.2131, 1.4590, 0.2749, 0.8824, -0.8286, 0.9989, 0.5599, -0.5099]]], dtype=oneflow.float32)
cpu:1, oneflow.Size([1, 2, 8]),
tensor([[[-0.7676, 0.4519, -0.8810, 0.5648, 1.5428, 0.5752, 0.2466, -0.7708],
[-1.2131, 1.4590, 0.2749, 0.8824, -0.8286, 0.9989, 0.5599, -0.5099]]], dtype=oneflow.float32)
cpu:0, oneflow.Size([1, 2, 8]),
tensor([[[ 0.6068, 0.1986, -0.6363, -0.5572, -0.2388, 1.1607, -0.7186, 1.2161],
[-0.1632, -1.5293, -0.6637, -1.0219, 0.1464, 1.1574, -0.0811, -1.6568]]], dtype=oneflow.float32)
需要注意的是,不能直接通过 python xxx.py 的方式执行上述代码,而需要通过 oneflow.distributed.launch 启动。此模块可以方便地启动分布式训练,在终端中执行下列命令 (假设上述代码已经保存至当前目录中的名为 "2d_sbp.py" 的文件中):
python3 -m oneflow.distributed.launch --nproc_per_node=4 2d_sbp.py
nproc_per_node 指定为 4 来创建 4 个进程,模拟共有 4 个 GPU 的情形。关于此模块的详细用法,请参见:用 launch 模块启动分布式训练。
完整代码如下:
Code
PLACEMENT = flow.placement("cpu", [[0, 1], [2, 3]])
BROADCAST = (flow.sbp.broadcast, flow.sbp.broadcast)
BS0 = (flow.sbp.broadcast, flow.sbp.split(0))
model = nn.Sequential(nn.Linear(8, 4),
nn.ReLU(),
nn.Linear(4, 2))
model = model.to_global(placement=PLACEMENT, sbp=BROADCAST)
x = flow.randn(1, 2, 8)
global_x = x.to_global(placement=PLACEMENT, sbp=BS0)
pred = model(global_x)
local_x = global_x.to_local()
print(f'{local_x.device}, {local_x.shape}, \n{local_x}')